If we wanted to send an email with some attachments then we can do this, nothing easier. If we wanted to use emojis in the filename of an attachment, then, in most cases, we can do this as well. But how did we end up here, has this been always possible? Let’s dig in!
Email attachments are one of the most used email features but this hasn’t always been the case. In the dark ages of email, messages were only plain text ASCII, so no-no to attachments. Today we assume that attachments became possible with the addition of Multipurpose Internet Mail Extensions (in short MIME) that was described in RFC1341 back in 1992. This is not quite accurate as well. The first attachments were actually uuencoded files included in the plaintext message body that pre-dates MIME. And in fact modern email applications often still support these kind of attachments.
Unsurprisingly the uuencoded attachments in non-MIME messages have a limited range of characters that can be used in the filename. Basically just plain ASCII (No emoji. Total loser). File naming was much simpler back in the day.
An RFC822 formatted email message with a text part and an attachment called test.txt would look like this (↵ marks newlines):
From: ...↵
To:...↵
Subject: This is a test message↵
↵
Test content↵
↵
begin 644 test.txt↵
#0V%T↵
`↵
end↵
And when opening such message with a modern email application we can indeed see that there is an attachment called test.txt attached.
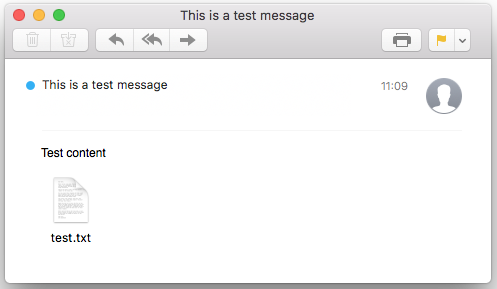
These prehistoric attachments are not too interesting though (unless you’re a phisher wanting to bypass some attachment related security checks), so let’s move on.
As already mentioned, 1992 gave us MIME and a standardized way to include non-text parts in a message. This is also the attachment system as we know it today – you have a multipart data tree where each node has its own separate header and body block. If the body block needs to include non-ASCII text then this is also possible, the content is encoded and the encoding scheme is noted in the header of that node. So the same uuencoded message could be converted to MIME like this:
Subject: This is a test message↵
MIME-Version: 1.0↵
Content-Type: multipart/mixed; boundary=abc↵
↵
--abc↵
Content-Type: text/plain↵
↵
Test content↵
↵
--abc↵
Content-Type: application/octet-stream;↵
name="test.txt"↵
Content-Transfer-Encoding: base64↵
↵
Q2F0↵
--abc--↵
And when opening such email message with an email client we see this:
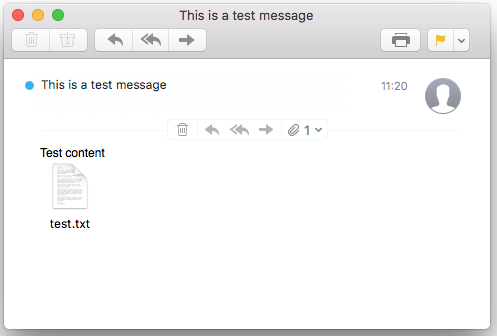
Looks pretty much the same, doesn’t it?
So where did the filename test.txt in the screenshot came from? If we look at the source then we see that the Content-Type header has an extra argument called name that defines the filename. This is already pretty awesome, we can use quoted parameters in MIME and inside the quotes we can use almost any (but no all) printable ASCII characters we like. So no filenames that have special characters like quotes and still lightyears away from emojis but we already can have words separated by spaces as filename. If we would like it so.
At this point the non-english speaking countries are starting to tag along and this means a new challenge: non-ASCII characters in message header. Message bodies already can use it, you can set a “charset” argument to the Content-Type header, use some encoding (usually either Base64 or Quoted-Printable) and you’re ready to send some mail, assuming you’re all right with using only latin characters in the subject line and also in the attachment filenames.
So in parallel to the RFC1341 a new standard was proposed, RFC1342 that defined something called “encoded-words”. It’s a construct that using only ASCII symbols presents sequences of encoded characters in any character set. If a word in our subject line includes a non-ASCII character, for example an umlaut “test messäge, awesome!” then the Subject header could be formatted like this
Subject: test =?ISO-8869-1?Q?mess=E4ge,?= awesome!
Unfortunately, encoded-words come with a restriction: these can only be used as an atom and not inside quotes as anything that is quoted is meant to be kept the way it is presented.
If we would try to use encoded-words as an attachment filename without quotes it would look obviously wrong
Content-Type: application/octet-stream;↵
name==?ISO-8859-1?Q?mess=E4ge.txt?=
Notice the double equal sign? This doesn’t seem right at all.
So even if we gained support for non-latin characters in the Subject line then we are still limited in our options when using attachment names.
We needed an alternative solution and even if it took some time we finally got there.
In 1996 RFC2045 re-defined the Content-Type header but this time there was no explicit “name” parameter mentioned. In 1997 RFC2183 fixed this by adding a new header Content-Disposition that has a parameter called filename, suitable for, as the name suggests, defining attachment filenames.
In parallel to RFC2813 another standard was released, RFC2814 that together with the newly defined filename parameter finally fixed the long standing issue of non-latin attachment filenames. This was done by introducing yet another encoding scheme, Parameter Values and Parameter Value Continuations. When encoded-words used equals sign to indicate encoded characters and question mark to separate different parts of the scheme then Parameter Values use percent sign for encoding and single quote for separation.
Content-Disposition: attachment;↵
filename*=iso-8859-1''mess%4Ege.txt
Asterisk in the end of the parameter name indicates that the value uses Parameter Value encoding.
The same mechanism allows splitting long values into multiple chunks (thats the Continuation part) but this is not super important, so we will not cover it here. What is super important, is that the changes done in 1997 allow us to finally use emojis in filenames even if emojis as characters weren’t invented yet.
If we want to use a filename like “😁😂’.txt” then this is totally doable with the Parameter Value scheme. We need to provide correct charset and also encode the bytes in the value. It would look something like this:
Content-Disposition: attachment;↵
filename*=utf-8''%F0%9F%98%81%F0%9F%98%82.txt
On a good day this would end our journey because this is exactly how emojis in attachment filenames are supposed to work. In the real world things are not as easy.
Let’s send a message with an attachment name formatted this way to for example an email address hosted by QQ, a huge chinese email provider. How does the QQ interface display us the attachment? Assuming that the chinese are accustomed to using non-latin characters then this should work as intended? No?
Apparently no. It seems that QQ does not handle these characters at all, as this is how the attachment is shown in the web interface
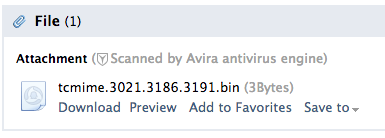
Do you really have to keep using only latin characters when sending to a chinese service? Fortunately not. QQ webmail does support non-latin characters, including in attachment names, they just do not follow the standards for that.
I guess that they haven’t yet catched up with the latest trends of 1997
It appears that they still go with the Content-Type header with name parameter where they allow to use encoded-words in quotes.
So what you really need to do in this case would be to add the same filename to attachment headers twice. Once to Content-Disposition, using the standard Parameter Value encoding and once to Content-Type, using encoded-word encoding.
Content-Type: application/octet-stream;↵
name="=?utf-8?Q?=F0=9F=98=81=F0=9F=98=82.txt?="↵
Content-Transfer-Encoding: base64↵
Content-Disposition: attachment;↵
filename*0*=utf-8''%F0%9F%98%81%F0%9F%98%82.txt↵
And the result is exactly what we wanted, an attachment named with emojis.
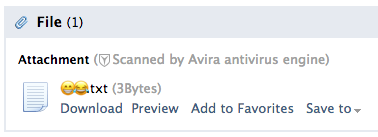
More standard obeying email clients would use the name shown in Content-Disposition. QQ and some other less standards-savvy clients would use the Content-Type header.
Nodemailer obviously handles all of this out of the box.
Hello,
First of all, great post.
Wonder if you can help me, i want to send an pdf file through MIME in visual Basic.
Like this:
MimeHeader = MimeFile.CreateHeader(“Content-Transfer-Encoding”)
Call MimeHeader.SetHeaderVal(“base64”)
MimeHeader = MimeFile.CreateHeader(“Content-Disposition”)
Call MimeHeader.SetHeaderVal(“attachment; filename=” & “åäöåäö.pdf”)
Call Stream.Open(AttachmentPaths(i), “binary”)
Call MimeFile.SetContentFromBytes(Stream, “application/octet-stream”, ENC_IDENTITY_BINARY)
Call MimeFile.EncodeContent(ENC_BASE64)
As you can see i want to have a file with UTF-8 characters “åäöåäö.pdf”
But I cant make it work, do you know what i have to do to manage this?
Thanks!
You would have to encode the attachment name by rfc2231, in which case your header code would look something like this:
Call MimeHeader.SetHeaderVal(“attachment; filename*=” & “utf-8”%C3%A5%C3%A4%C3%B6%C3%A5%C3%A4%C3%B6.pdf”)
So what you really need to do in this case would be to add the same filename to attachment headers twice. Once to Content-Disposition, using the standard Parameter Value encoding and once to Content-Type, using encoded-word encoding.
Can you please provide some example of encoding filenames in Content-Disposition and Content-Type.
I tried MimeUtility.encodeText and URLEncoder.encode but not working.